
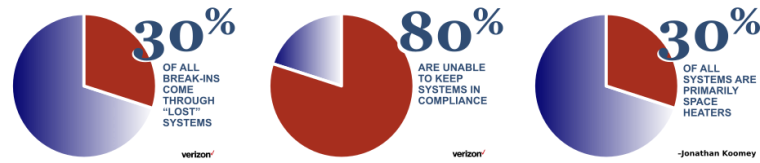
Keeping track of servers in a large organization is a daunting task, and one which many organizations don’t do well – sometimes with grave consequences. There are lots of reasons why systems get “lost”. If you can keep track of your servers, you can decrease your chances of an intruder getting in by 30%. In this article, we’ll look at what happens when you lose servers, and some of the ways people lose servers.
Consequences When You Lose Servers
At first thought the idea of losing a system might seem ludicrous. I mean, you paid good money for it, you had to supply it power and cooling, and you had your administrators spend time to install it, your network team wired it up, you assigned it an IP address, and then you lost track of it somehow. The trick is that you put it in a data center with lots of other systems – and then it becomes a bit more like looking for someone else’s car in a monstrous parking garage. It’s not as hard as you might think to lose track of it.
What are the consequences of having “lost” systems:
- They are not in your configuration management system (Ansible, Chef, Puppet, etc)
- They are not kept up to date with the latest security patches – adding to insecurity
- They occupy software licenses
- They consume power and cooling, raising costs and adding to greenhouse gases.
- They become “zombie servers” – contributing to the 30% of servers that are primarily space heaters.
How to Lose Servers
Here are a few ways you can lose track of a system:
- It was part of a failed IT project. Somehow it doesn’t become quite as compelling and exciting to tear down a failed IT project as it was to put it together. Likely there was no plan put together laying out exactly what to do when the project failed. Those people who survive working on such projects try and quickly find something else to do. This leaves reclaiming servers and services to a low priority hit-or-miss effort.
- It was part of an experiment. It’s important for IT shops to keep up with the latest in technology and continue to learn about new technologies. One of the best ways to learn about a new technology is to experiment with it. Unfortunately such experiments are often low priority, and can easily never be added to official lists, or become forgotten as priorities change and staff moves around. Virtual servers make this much more likely, often resulting in VM sprawl. Similar things can happen with cloud instances which are easier to create. On the other hand, public clouds create an expense trail that makes this less likely – and more costly.
- It was part of an obsolete production service. Most IT shops rightly spend most of their effort adding new value and maintaining existing services. This typically means that the efforts to eliminate obsolete services are given lower priority. When a service is replaced by a new one, it is not always clear if the new service is going to provide everything the old service provided. If that happens, then the old servers might get turned back on in an emergency effort to solve a problem, and not be put back on the books. People go on with their lives.
- It was surrounded by mythology. Certain servers and services have been known to acquire a certain mythology around them. “The last time I messed with that server, we were down for 24 hours”. “The last guy to mess with that service lost his job”.Sometimes when systems surrounded by IT mythology need to be turned down, people rush to drive a stake in its heart, but sometimes they’re covered by a “somebody else’s problem field”. When it comes down to it, sometimes people would rather pretend they didn’t know anything about them than volunteer to do something about them.
There are no doubt many more creative ways to lose a server and we’d love to hear your favorites.
Stay tuned and in future blog posts we’ll cover how to find lost servers, and how to continuously keep your servers in security compliance with security automation from the Assimilation System Management Suite.
Please note: I reserve the right to delete comments that are offensive or off-topic.