
This is a reposting of an article I wrote dated Aug 30, 2017 orignally found at https://www.peerlyst.com/posts/the-authproxy-method-of-sharing-secrets-safely-with-containers-alan-robertson. Sadly this site is no more.
In a previous article, I explained how Custodia had created a ground-breaking way of sharing secrets to applications running in containers. In this article, I explain a simpler authentication proxy (“authproxy”) method for sharing secrets with containers which was uses Custodia’s cool UNIX domain socket trick. The result is a simpler, easier-to-deploy system with most of the advantages of the Custodia method.
Custodia authenticates docker services using things it discovers through a UNIX domain socket and the information which can be gotten from /proc/<pid>/ and docker inspect. This provides a method of authentication which is analogous to looking at the process’ DNA, or the cyber-analog of biometrics.
Custodia then proxies the connection to the secrets repository and provides its own configuration of which entities have access to which secrets. This full proxy mechanism adds another layer of complexity and configuration to the situation. This complexity shows up in terms of additional logical servers, additional certificates, additional code and additional configuration. In order to understand the rules of which application has access to which secrets, one must both understand the Custodia configuration and the configuration of the downstream vault. This increases the possibility of failures and errors in configuration – not to count errors in understanding the configuration.
In the authproxy method, applications connect to an authentication proxy running on each VM to get access to the authentication tokens that they need to connect to the vault. The applications then connect to the vault directly. Because the authentication proxy is running on each host system, it is able to use the same methods that Custodia does to authenticate its clients.
A diagram representing the authproxy architecture is shown below:
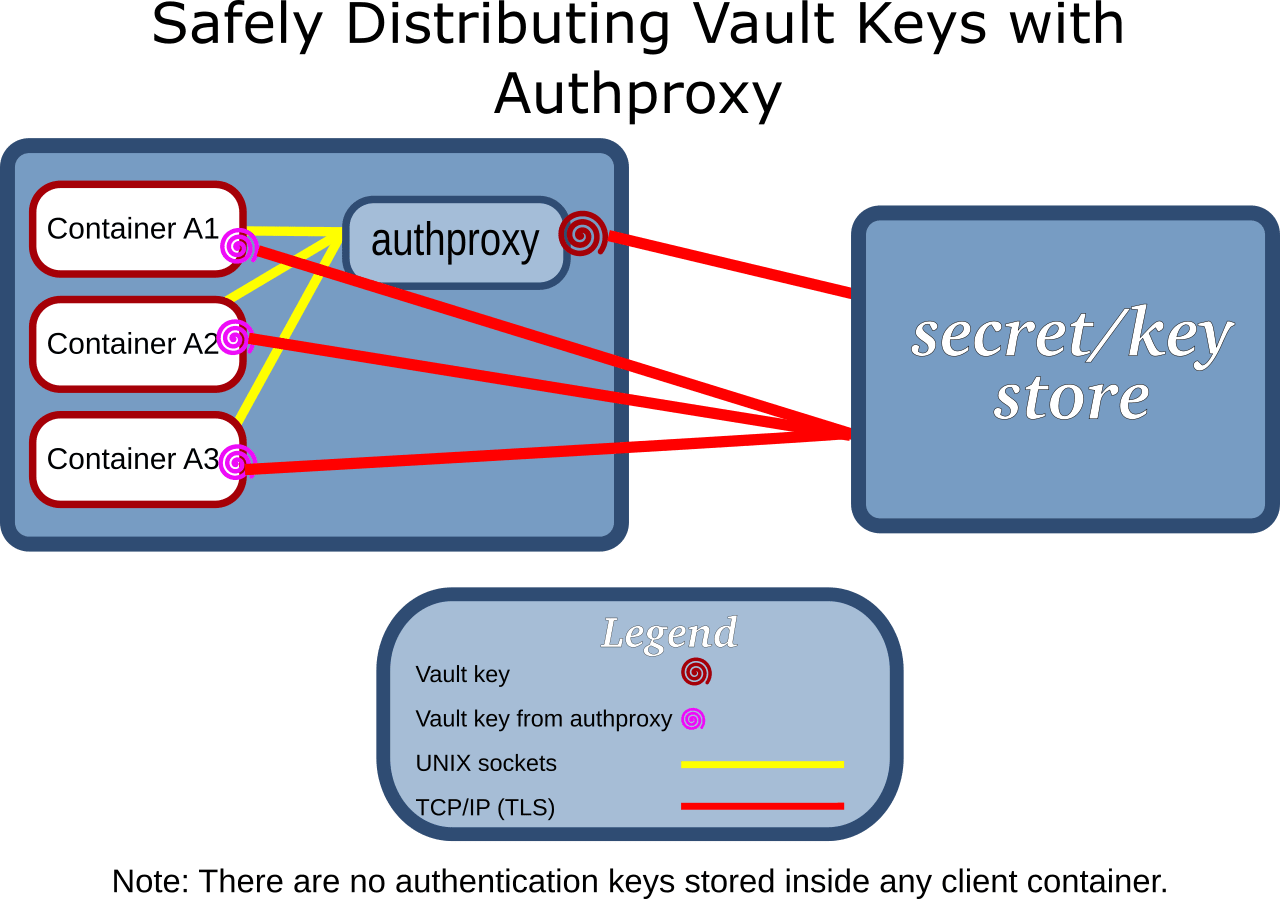
Secret Request Flow
In this example, container A wants a secret named “SecretA”. Here’s how that would go:
- The application in container A connects to its authentication proxy (the one running on its host), and sends no data.
- The authproxy service receives the connect request (without data), and deduces from the connecting process information that it is “ServiceA”.
- The authproxy connects to the Vault, authenticating itself as “authproxy” using the authproxy Vault key it has access to from the host. This identity has been given read-only access to the tokens its clients will need to connect to the vault.
- The authproxy asks the Vault for the Vault key that ServiceA needs to connect authproxy to the Vault.
- The authproxy sends the Vault key for ServiceA to the ServiceA client.
- ServiceA connects to the Vault, using the vault key it got from the authproxy.
- ServiceA asks for as many secrets as it needs from the Vault, and these requests are permitted or denied on the basis of the Vault configuration for ServiceA associated with the vault key that authproxy gave it.
Just like the Custodia case, there are no authentication tokens stored in the containers. Unlike the custodia case, the clients in the containers have access to those tokens, and like Custodia, they are not stored in the containers.
However, since it’s only performing the authentication function and supplying an identity token to the applications, it doesn’t need to read any data from the socket. Instead, it just gets the information from SO_PEERSEC, /proc/<pid>/ and docker inspect and uses that to identify and authenticate the application. Once authenticated, it sends the identification token to the client and closes the socket. So the client never sends data to the authproxy, and the server never listens to data from the client. One interesting effect of this is that the authproxy server never has access to potentially tainted data – eliminating several classes of potential attacks.
What kind of information does authproxy have access to for authentication?
There are basically three interesting sources that authproxy (or Custodia) has to authenticate the client:
- UNIX domain socket SO_PEERCRED and SO_PEERSEC information
- /proc/<pid>/* information for the pid listed in the SO_PEERCRED information
- docker inspect information
Potentially interesting UNIX socket Information
This information is limited to four pieces of information from SO_PEERCRED and SO_PEERSEC socket calls.
- pid – the process id of the connecting process at the time they connected
- uid, gid the user and group ids of the connecting process at the time they connected
- security context – the Linux security context of the connecting process.
Since sockets can be passed around in a variety of ways, this information reflects the information about one particular process at the time they connected. The security context is potentially more interesting because of the original connecting process’ inability to forge or modify it.
Potentially interesting /proc/ information
- /proc/<pid>/cmdline – client command line (client can change this)
- /proc/<pid>/cgroup – identifies which container they’re running in
- /proc/<pid>/exe – full pathname of the binary the client is running (client cannot change this)
- /proc/<pid>/uid_map (and gid_map) – mapping of container uids/gids to host uids gids
- /proc/<pid>/status – provides parent process id and real, effective, saved and filesystem uids and gids
Since this information relates to the process at the time they connected, and not some other potential process which has been given the socket, like the socket information, it is also a point-in-time snapshot of one particular process. If the authproxy server responds quickly to connections, this information is difficult to subvert – particularly in the container environment.
Potentially interesting docker inspect information
The docker inspect command provides information about the container that the client is running in. This information is difficult for a hostile client to subvert or cause you to misinterpret.
- Name – the name of the image
- Path – full pathname of the container’s “init” process
- Args – the arguments given to the init process in the container
- State.Pid – the process id of the container’s “init” process
- Config.Hostname – hostname that this container is running in
- Config.Image – the image that created the container that the client is running in
- Image – the SHA256 sum of the image named in “Config.Image”
There are a variety of ways that this information can be used (particularly in an SELinux environment) to provide high confidence that the connecting client is who they claim to be. For example, if the correct SELinux rules are provided, one can assure that even if somehow the application is subverted, the security context for an attacker’s process would not be correct, and they would fail authentication. This is a very powerful assurance. Another piece of information that’s nearly impossible to subvert is “is the client the same pid as “State.Pid” from docker inspect. Exactly which pieces of information provide what degree of certainty – and why – is an interesting topic – perhaps for future article.
There are really two parts to the authentication server, the server itself, and the code to provide the socket, /proc, and inspect information for it. Because the server doesn’t exchange packets with the client, it is extremely simple. I created a prototype implementation which was around 30 lines of Python. The code to obtain and format all the “interesting” information is quite a bit longer, but still very straightforward. Zero of that interesting information can be tainted by the client. There is a potential race condition that an attacker can potentially make the socket pid and /proc information less trustworthy, but it’s difficult to carry out in a container environment, and the time to carry it out is very short. Because the authentication is effectively immediate, the authproxy code is more difficult to exploit than some other methods. You can read more about it in this discussion. However, as I noted in the previous article, these values combined together provide a great degree of confidence that the client is who they say they are. This is very similar to Custodia in this respect.
As far as I know there are not any published implementations of this method, but it’s quite straightforward. It provides the advantages that I mentioned in the Custodia article, but is much simpler than Custodia, and has a near-zero attack surface.
Please note: I reserve the right to delete comments that are offensive or off-topic.