
The three pillars of IT security are confidentiality, integrity, and availability. Most of the press coverage is all about confidentiality – at least until we have an airline or two or three have trouble with availability ;-). Of course, availability is also a key dimension of server management with significant operational dimensions. Those of you who know me, know I have deep expertise in availability – having spent 15 years in high availability. Unsurprisingly, in this post, I’m going to concentrate on availability – and the necessity of monitoring everything, and knowing for certain that you’re monitoring everything.
Monitoring Everything
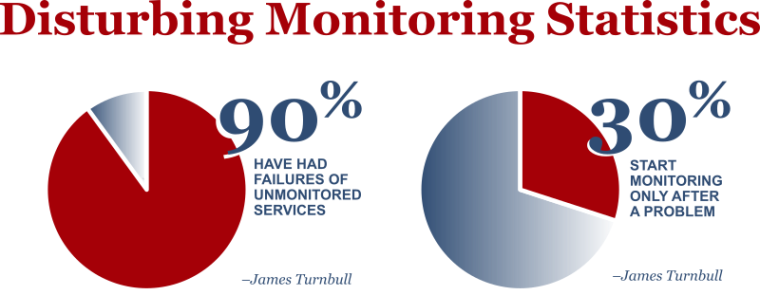
The logic is simple really, if you’re offering a service on a server you ought to be monitoring it. But for a variety of reasons, this doesn’t happen like it should. According to James Turnbull’s monitoring survey 90% of organizations have discovered that they’re not. Worse yet, 30% of IT shops admit they don’t start monitoring until they have problems. If you’re wondering if his statistics are biased – or if it covers typical IT shops – it doesn’t. In fact, it primarily covers what you’d call leading edge shops – largely those running Puppet or Chef or similar.
This is certainly consistent with the views the audiences to my Assimilation talks have expressed. There is a decided view that the real world is worse than this, perhaps much worse. Like somehow those statistics aren’t bad enough? ;-).
Is there a reason not to monitor a service on a production server? I would argue that there isn’t. If you don’t need the service, don’t provide it. If you drop a service, you decrease the attack surface for intruders. If you do need the service, then you need to monitor it – period.
Tools For Monitoring
There are plenty of tools out there for monitoring – Nagios, Icinga, Zabbix, OpenNMS and so on. And there are plenty of tools for deploying and configuring them – Ansible, SaltStack, Chef, Puppet and others. In spite of the presence of so many tools there seems to be a gap – it still isn’t getting done – in a big way.
One reason might be that it’s easy to forget to set up monitoring, or that the people involved in setting up services might not be monitoring experts. Another is that the tools being used are difficult to configure (Nagios certainly has that reputation), or that the deployment tools aren’t ideal for configuring monitoring (anecdotes suggest this to be a factor). Other possible reasons include time pressures, lack of knowledge of local services, and difficulty in monitoring services.
All these things make it less likely that monitoring gets done. Evidence suggests that these factors and more are working very effectively to keep the job from getting done.
Monitoring Questions
Here are some questions for your monitoring service:
- Does it discover every service and keep that discovery up to date?
- Does it automatically monitor services it knows about?
- Can you easily tell what you’re not monitoring?
Assimilation Monitoring
If you can’t answer yes to all these questions, then you should look into the Assimilation System Management suite. Its monitoring does all these things, scales simply like nothing else and the suite as a whole does much, much more than simply monitoring. It’s a snap to install and gives you immediate relief from these headaches – and more.
How we approach these issues in the Assimilation Suite is that we discover every service being offered on the servers (using netstat and similar), and we monitor everything we know how to monitor automatically. This makes our basic zero-effort coverage very good indeed. And since we discover everything and monitor everything automatically, you don’t have to tell Ansible, Chef and friends what needs monitoring – further simplifying your life. In fact, we don’t care if you use one of these at all. There are plenty of reasons to use such tools, but we care much less than most monitoring tools – since we require nearly zero configuration – and only on one system.
But we go further than that. Because we know all the services on every machine, and we know for certain what we are monitoring, it’s a simple query to ask what’s been missed. Just run assimlcli query unmonitored and be happy – or at least know the truth.
You can then add monitoring for those services over time, and then they’ll be monitored too. But even if you decide against my advice to not monitor a service, at least it’ll be a deliberate and considered decision which can be reviewed periodically just by running the assimcli query again.
Please note: I reserve the right to delete comments that are offensive or off-topic.